Text categorization (also known as text classification, or topic spotting) is the task of automatically sorting a set of documents into categories from a predefined set.
Text categorization is a complex problem to solve, for solving it you need to provide a variable for each important word in your text. Maybe not stopwords or very common words, but at least you need to include any word that can help your classifier to identify the topic on your text. So if for example your text is talking about politics and you find the word “party” you need to include this word as a variable for your vector space model. And that can happen with many words and specially if you work with a high number of topics. So text categorization problems are in fact multidimensional problems.
1. K-Nearest Neighbors
K-nearest neighbors (KNN) method [1] is used in many supervised learning classification problems. As you can see in Figure 1, the idea is pretty simple. The method assigns a new point to a category by comparing it with other points already classified. This category will be chosen by looking at the categories of the K-closest neighbors. In practice, the choice of k is determined by the cross-validation method. Although it also depends on the dataset.
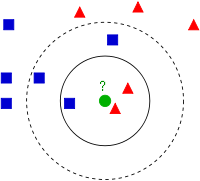
Figure 1. KNN Example in a bidimensional space.
In the same way that you can use this algorithm with a bidimensional space, you can use this same algorithm with multidimensional spaces and find the closest neighbors to a new vector by computing the euclidean distance (see Fig. 2).
Figure 2. Euclidean distance
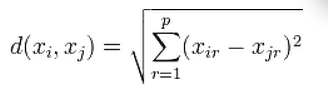
2. Why Lucene?
Lucene [5] is a free open source search and retrieval application available through the Apache Software Foundation (ASF) and is released under the Apache Software License. Lucene itself is an application-agnostic text indexing and search toolkit — it doesn’t contain functionality such as crawling and document parsing. Comparing with machine learning packages like Weka [4] it offers a much better performance since Weka is designed and optimized to perform with functions taking 1 to 20 parameters. Weka can also calculate text categorization problems, but you will need to provide the program with lots of memory and most of the classifiers included in Weka will not work anyway.
So which strength is giving us Lucene? In this specific use case of text categorization Lucene is giving us an already implemented text vector model. It allows us to create queries by text documents and search for closest text documents to the one you are trying to categorize.
3. Implementing KNN in Solr/Lucene
For this particular project I have implemented a solution written in Java that is available in the following github url https://github.com/raimonbosch/knn.classifier.
In this project you can find two indexers: ArffSolrIndexer and TwentyNewsSolrIndexer. Both of them are processing set of documents and creating a lucene index with those documents. For each lucene document we assign a category or a list of categories. The document contains a text that for instance could be a movie review assigned to a list of movie categories, or it could be also a journalistic article assigned only to one topic. During the indexing process we can define how many folds we want to have i.e. if we have 10 folds the indexer will create 9 folds of classified documents and 1 with unclassified documents.
In the second step called KnnClassifier we query the data inside this index and we try to guess the category of the unclassified documents by using the KNN algorithm. For each document in the unclassified fold we try to find the k-closest neighbors in the already classified document folds. And finally, we guess the category by analyzing the category assigned in the k-closest neighbors.
In order to measure the effectivity of our classifier we can compare the category computed by KNN algorithm with the original category assigned in the dataset. This means that we are using the cross-validation method for this.
3.1 Installation instructions
To install this code in your machine you will need at least OpenJDK and Maven2. After installing this two dependencies you only need to clone the repo in your machine by running:
git clone https://github.com/raimonbosch/knn.classifier $HOME/knn.classifier
And then you can compile the code by using maven (this will download all the dependencies that you might need to run the code):
cd $HOME/knn.classifier
mvn clean install
You can try the program with the IMDB dataset:
http://en.sourceforge.jp/projects/sfnet_meka/downloads/Datasets/IMDB-F.arff/
Create the index by executing:
java -Xmx512m -Dfile.encoding=UTF-8 -jar target/knn-classifier-1.0-SNAPSHOT-jar-with-dependencies.jar –action=index –input=/tmp/IMDB-F.arff –output=/tmp/solr –solrconf=./src/main/resources/solr/
Run your classification:
java -Xmx512m -Dfile.encoding=UTF-8 -jar target/knn-classifier-1.0-SNAPSHOT-jar-with-dependencies.jar –action=knn –input=/tmp/IMDB-F.arff –output=/tmp/solr –solrconf=./src/main/resources/solr/
In the output you will see the precision of the classifier with this given dataset. In the params you can include also a different K for the KNN algorithm by using –topTerms param. Also you can customize the number of folds by using –folds params. Default values are topTerms=3 and folds=10.
—————–
Total matches 4822 out of 12091
Accuracy is 0.39880905
—————–
For more detail in the execution params and how the code works I recommend to read the code inside EntryPoint.java.
3.2 ArffSolrIndexer: Indexing IMDB movie reviews
The ArffSolrIndexer is designed to process .arff formats. This is the format used in Weka (the most popular machine learning library for java [4]). The idea of this format (see Fig. 6) is to define a series of attributes one of them called numerics and other called nominals. The nominals usually are used to define the categories of a given text to classify (@attribute Comedy {0,1}). The numerics are used to define all the words that can appear in a text to classify, so we create one variable for each word. At the end of the Fig. 6 you can see how the documents are defined ({4 1,25 1,30 1,32 1,34 1,48 1,3381 2,287 4}). That defines how many times appears each numeral or nominal. “4 1” means that the nominal 4 has the value 1 (so it is not 0), “287 4” that the numeric 287 appears 4 times in a text.
|
@attribute Comedy {0,1} @attribute Thriller {0,1} @attribute julia numeric @attribute roberts numeric @attribute friday13 numeric … @attribute zeland numeric @data {4 1,25 1,30 1,32 1,34 1,48 1,81 1,87 1} {23 1,53 1,93 1,182 1,351 1,403 1,404 1,450 1,463 1,478 1,506 1,622 1} … {17 1,58 1,233 1,350 1,413 1,534 1,631 1,759 1,832 1,906 1,962 1,1005 1,1009 1} |
Figure 6. Example of ARFF format for IMDB (movie review database)
To translate this information to a lucene index you can use a the class inside the Weka library weka.core.Instances that is able to read this file and give the words associated to each document to recompose the original text. Although you cannot recover the original order of the text this is not important because the algorithms in Lucene are working also with term frequency.
So in ArffSolrIndexer.java you can see how this information is mapped into a Lucene index that can be used in a classifier step.
3.3 TwentyNewsSolrIndexer: Indexing news articles
This dataset is available in http://qwone.com/~jason/20Newsgroups/. This dataset is the one used to write tests for the Mahout library. Mahout is another Apache project that is trying to write machine learning problems using MapReduce [3]. The structure of this data is far simpler than .arff formats and you can have the original word order of the texts. The dataset is organizing a set of text files in different folders (see Fig. 7). Each folder represents a category.

Figure 7. Structure of 20news dataset
For more details you can read the code in TwentyNewsSolrIndexer.java. Basically it receives the directory root and it creates a lucene index of text documents assigning a category depending of the subfolder name.
3.4 KnnClassifier: Classifing documents with MoreLikeThis
Given a set of documents where some of them had no category assigned and some of them yes. The goal is to create an operation able to give us the document similarity between this unclassified document and the k-closest documents already categorized in our search index. With this operation we will be able to determine a category by choosing the most repeated category on this k-nearest neighbors.
For this operation you can use the MoreLikeThis search handler from Apache Solr that is specifically designed to retrieve document similarity.
SolrQuery query = new SolrQuery();
query.setRequestHandler(“/mlt”);
query.setQuery( “id:” + docID );
query.setParam(“fq”, “is_categorized:1”);
query.setRows(k);
QueryResponse qr = server.query(query);
As you can see we are building a SolrQuery that calls to the requestHandler /mlt (MoreLikeThis) and searches all the documents similar to docID inside the documents group marked with is_categorized:1. The setRows(k) is to determine how many neighbors will you analyze to determine the category of this unclassified document.
The main difficulty of this approach is that is obligating to you to include all the unclassified documents inside your search index in order to perform this “similarity search” properly. But basically you need to implement an indexer that recognizes which documents are not yet categorized and which of them are already categorized and use this filter fq=is_categorized:1 to make the distinction during the search.
For more details you can read the code in KnnClassifier.java.
4. Results evaluation
4.1 Effectivity of this implementation
The effectivity obtained with the first movie reviews dataset is 39.88%. This means that for each unclassified document we can guess correctly its category 4 of each 10 times. The dataset of movie review is quite complex since it assigns more than one category (sometimes until 6) for each text and also it has not enough data: only around 120.000 documents. This ratio can be improved by adding more data or using weights to give more probabilities to the more often neighbors.
With the second dataset of 20News the results are lot better since we only have to calculate one category per document. In this case we have a precision of 86.99%.
4.2 Efficiency of this implementation
The efficiency in both solutions is correct. The IMDB dataset has 120.918 million of documents and the index can be created in 104 seconds. After this it can classify a total of 12.091 documents in 171 seconds, spending 14 milliseconds for each classification.
4.3 Comparing with Weka
Weka is the machine learning library written in Java [4]. Weka is offering also a kNN classifier under the IBk package. The comparison was realized considering together the time taken to build the model and the time to classify N documents with cross-validation. To build the kNN model for IMDB dataset (see section 3.1) you need to provide to the Weka program at least 2.5GB of memory and it takes 143 minutes to build the model and finish the cross-validation classification tests. It reaches an accuracy of 58.53% (see Fig. 8). Although the Weka’s precision is far better to the implementation written in Lucene (most than 18% better). The execution time in Lucene is 28x times faster (5 minutes vs. 143 minutes).
| === Run information ===Scheme: weka.classifiers.lazy.IBk -K 1 -W 0 -A “weka.core.neighboursearch.LinearNNSearch -A \”weka.core.EuclideanDistance -R first-last\”” Relation: IMDB: -C 28 Instances: 120919 Attributes: 1029 [list of attributes omitted] Test mode: 100-fold cross-validation=== Classifier model (full training set) ===IB1 instance-based classifier using 1 nearest neighbour(s) for classificationTime taken to build model: 0.14 seconds=== Cross-validation === === Summary ===Correlation coefficient 0.0275 Mean absolute error 0.0127 Root mean squared error 0.1101 Relative absolute error 58.5306 % Root relative squared error 105.8204 % Total Number of Instances 120919 |
Figure 8. KNN Output in Weka.
This test was realized with 1-nearest neighbor. Is possible that adapting this k to 2, 3 or 4 neighbors this results could be better. More options have not been tested because the execution time takes too much and the point of this test is to demonstrate that a solution with Lucene is always faster than Weka (in exchange of accuracy).
5. Conclusions
The vectorial model offered by Lucene has a very good efficiency in terms of performance. It can classify huge quantities of text by using few GB of ram memory. The time efficiency is also very good, we were able to classify 12.000 documents in less than 3 minutes after spending only 2 minutes to create an index with 120.000 documents. Furthermore, this solution should be easily parallelized by splitting the dataset in different indexes. The bad news is that the accuracy was not very high at least with the datasets tested. When we were trying to classify texts assigned to multiple categories the accuracy was less than 40%. This number improved when the dataset was easier and only had one category per text, in that case we reached almost 90% of accuracy that it was still low. Obviously another way to improve this ratio accuracy is by using more data.
5.1 Future Work
For future work it would be interesting to test this kind of KNN classification done by Lucene for non-text categorization problems since the vector model offered and its MoreLikeThis functionality should work correctly for a set of arbitrary variables. Another interesting line of work is improving the KNN algorithm to improve the accuracy ratios, the concept of doing a weighted-KNN classification could be an strategy although I am sure that there are other state-of-the-art solutions to explore that could give us the accuracy ratio we are looking for. Also, it would be interesting to test this kind of solution with bigger datasets with 10 to 100 million of documents. It would be an interesting investigation to scale horizontally this solution by using a library like Hadoop [3,7].
6. References
[1] Wikipedia, “k-nearest neighbors algorithm”; http://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm
[2] Apache Software Foundation, “Lucene Similarity 2.9.0 API”, 2000-2009; http://lucene.apache.org/core/old_versioned_docs/versions/2_9_0/api/all/org/apache/lucene/search/Similarity.html
[3] J. Dean and S. Ghemawat, “MapReduce: simplified data processing on large clusters,” Communications of the ACM, vol. 51, no. 1, pp. 107–113, 2008.
[4] Machine Learning Group, University of Waikato, “Weka 3 – Data Mining with Open Source Machine Learning Software in Java”; http://www.cs.waikato.ac.nz/ml/weka/
[5] Apache Software Foundation, “Apache Lucene – Apache Lucene Core”, 2000-2009; http://lucene.apache.org/core/
[6] Apache Software Foundation, “Apache Lucene – Apache Solr”, 2000-2009; http://lucene.apache.org/solr/
[7] Apache Software Foundation, “Welcome to Apache™ Hadoop®!”, 2000-2009; http://hadoop.apache.org/
